 |
|
iCAN (Institute Collection & Analysis of Nanobody) has been created to expand and accelerate nanobody studies. Nanobody has family-specific sequence composition which can be mined to discover and design novel nanobody sequence. iCAN contains information on the collected 2490 unique nanobodies. The collection of the database covers all publically available nanobodies that we could obtain from all sources including academic publications and industry patents as well as that generated in our lab. To our knowledge, it is the first public database of nanobody. Information related to sequence, protein definition, accession number, activity, target antigen, patent description and link to databases like PDB, PubMed and other related databases are provided for the benefit of users. The database not only collects the nanobody information, but also provides tools for sequence alignment, and key words-based search. Comprehensive documentation of the database can be obtained from the Help page. Or you can find tutorials through the |
Sequences 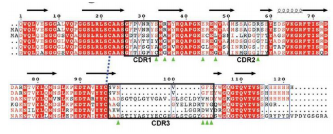 |
Patents  |
Structures 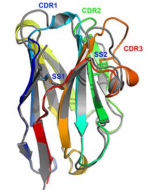 |
| © Institute of Life Sciences, Southeast University |